“A prudent question is one-half of wisdom.” — Francis Bacon
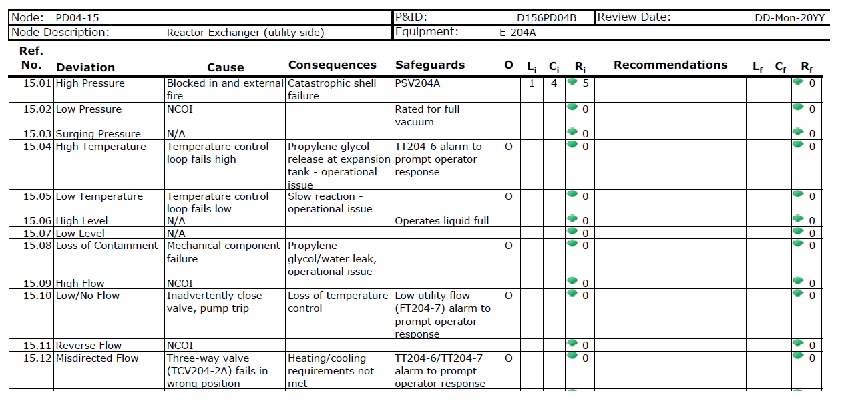
There are about a gazillion “best” ways to do HazOps. What they all have in common, however, is that they use worksheets that are set up as tables that look at deviations in a node. For each deviation, a HazOp team considers “Causes”, “Consequences”, “Safeguards”, “Severity”, “Likelihood”, and “Recommendations”, the heading of the table in a HazOp worksheet.
One of the jobs of a HazOp facilitator is to explain to team members that are new to HazOps what each heading means. Another job is to explain to experienced team members what each heading means, just in case they’ve picked up some bad habits.
Over the years, a set of questions has developed that are usually very helpful in helping team members understand their role in the HazOp: Answering these seven questions.
- Deviation
Is there a limit to this parameter in this node that is unsafe to exceed?
We belong to the school of thought that believes a HazOp should begin with a standard list of deviations. While there is likely to be disagreement between facilitators about what exactly should be on that list, we usually agree that each item on the list should be considered.
The first step is to decide if the deviation applies. There is always a pressure that is too high and a temperature that is too high. The others are all on a case-by-case basis. While it doesn’t hurt to know exactly what the unsafe limit is, it is enough to know that there is a limit and about what it is. When there is no limit (such as high level in a liquid-full pipe), mark the Cause as “N/A”.
-
Regarding causes:
If there is an unsafe limit, what specific failure or error would cause the node to go beyond that limit?
The cause should be a specific failure or specific error. It is not enough to say, “Control failure.” It should be more like “FC-552 fails high”. “Operator error” is not specific enough. It should be more like “Operator misaligns feed valves prior to start up.”
The failure of a safeguard is not a cause. A PSV sticking closed doesn’t cause high pressure, something else does. Neither is weather. Cold weather may be necessary to freeze the pipes, but cold weather is not a failure. Failure of the freeze protection is the failure.
Also, it is important for the team to look for causes outside of the node. The deviation happens in the node; the cause can happen anywhere. Finally, it may be that there are unsafe limits, say, the melting temperature of steel, but if the team cannot conceive of a failure that would cause the node to go beyond the unsafe limit, then mark the Cause as “NCOI”, no cause of interest.
-
Regarding consequences:
So what? What are we worried about happening?
These questions help team members ignore the safeguards, which they should when considering consequences. It also helps the team to consider a consequence in two parts: an event and its impacts. Process safety events are typically fires, explosions, or toxic releases, although some organizations also consider falls or ergonomic stresses. Everything else usually can be described as an “operational issue”, a “maintenance issue”, or a “quality issue”.
If a team member gets stuck on the idea that a safeguard renders an event “impossible”, or argues that “it can’t explode, it has an atmospheric vent”, good follow up questions are, “Why does it have that safeguard? What is that safeguard protecting against?”
Finally, like causes, look for consequences outside of the node as well as within the node. The deviation happens in the node; consequences (events) can occur anywhere.
-
Regarding severity:
How bad would it be if it did happen?
As engineers, we care about events because we are usually only in a position to address events: fires, explosions, or toxic releases. People don’t really care about events, though; they care about their impact on personnel, the community, the environment, or in some organizations, assets. It turns out that it is not the event that defines the severity, but its impact on various receptors.
-
Regarding safeguards:
Why doesn’t this happen all the time?
Anything that answers the question, “Why doesn’t this happen all the time?”, is a safeguard. That includes process design features, engineering controls, administrative controls, and special PPE. They don’t have to be perfect to be a safeguard.
The only thing that shouldn’t be eligible for consideration is the thing that failed, causing the hazard in the first place. A high-level alarm from a control loop should not be listed as a safeguard if it was the failure of the control loop that caused the high level in the first place. Likewise, a procedure should not be listed as a safeguard if it was a failure carrying out that procedure that caused the problem.
-
Regarding likelihood:
What is the likelihood that this event will occur with these impacts?
Likelihood in a HazOp is not a probability; it’s a rate. How often will the event we’re afraid of happen and also result in the impacts we’re afraid of?
This likelihood depends first on the likelihood of the initiating event, which is why it is important to describe initiating events as specific failures. We can find data that let’s us estimate the frequency of a control loop failure that causes high pressure; there is rarely any data that would allow us to estimate of the frequency of “high temperature” that causes high pressure.
The likelihood further depends on the probability that the safeguards will actually work to prevent final event. Remember that nothing is perfect; everything has some probability of failing, even relief valves and open vents to atmosphere
-
Regarding recommendations:
What can be done to reduce the risk to a tolerable level?
Risk is a function of consequence impact severity and likelihood. However an organization defines its tolerable risk, nothing needs to be done when the risk of a hazard is tolerable. You may, but you don’t need to. There are usually bigger fish to fry.
Remember, every recommendation made during a HazOp required by the Process Safety Management Standard, 29 CFR 1910.119, must be resolved. It doesn’t necessarily have to be implemented as proposed by the HazOp team. If it isn’t, though, there has to be written justification for why it is unnecessary or why some other measure is better. So, every recommendation creates work for someone. If the recommendation will not reduce the risk of the hazard, it should not be made in a HazOp. Likewise, if the recommendation cannot be done, it should not be made.
If the risk is too high – intolerable – then recommendations that will reduce risk and can be done must be made. It may be the HazOp team, while qualified to identify hazards, is not qualified to make the best recommendations. At the very least, then, recommend that something needs to be done before you kick the can down the road.
Seven Columns, Seven Questions
Eventually, all new HazOp teams get into a groove and manage to work their way through a process. These seven questions, one for each of the common fields in a HazOp worksheet, will help your HazOp teams to find their groove.